Practical SOA / microservices - Hydration - Part 1
Oct 01, 2014
The Problem
One of the problems we ran into building a system around a service oriented architecture was having multiple services returning the same type of data. The example that we'll use is a shopping site. Within a shopping site, we can conceive of multiple services that return list of products:
- Search
- Recommendations
- User's favorites
- Line items in an basket or invoice
- Various lists (new items, on sale, staff picks, ...)
- Probably more...
You can argue that some of these should be inside single service. If you think they should all be one service, well, I hope you'll find this post interesting nonetheless.
We want a product to look the same regardless of which service it comes from, without duplicating the display logic / view model. For example, a simple product response always look like this:
{
"id": "9001p",
"name": {
"en": "Dune"
},
"type": "book"
}
(I'll look at what happens when you want slight differences in the response later)
Possible Solution
We're building an endpoint which is responsible for returning the user's favorite products. We've decided to put this logic+data with other user-specific stuff. To get products out of it, we either make users aware of products, or make products aware of users:
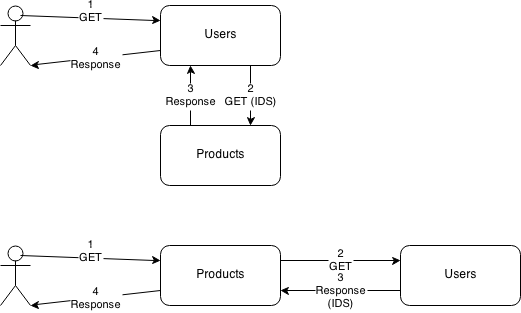
Even if a public API is being used between the two services, neither of these solutions seem ideal to me. Furthermore, we're introducing the performance hit of another HTTP call.
Hydration
The solution we ended up using is a JSON-specific form of Edge Side Include (I implemented it, but I'm not the one who came up with it). At first glance, it looks like a minor variation of the above, but I'm hoping I can convince you otherwise.
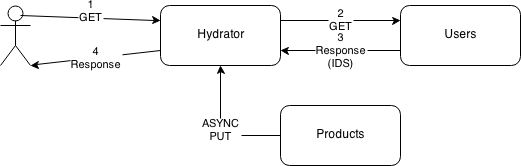
Here's what the response from the users service looks like:
{
"page": 1,
"total": 54,
"results": [
{
"!ref": {
"id": "9001p",
"type": "product"
}
},
{
"!ref": {
"id": "322p",
"type": "product"
}
},
...
]
}
It also includes a X-Hydrate header with a value of !ref - which tells the hydrator that (a) this response needs to be hydrated and (b) the name of the hydration key. The hydrator should remove the header before sending out the response.
Asynchronous
It isn't absolutely necessary, but to me, one of the key points here is that the products are asynchronously pushed to the hydrator. It further reduces coupling, it vastly improves performance, and its a huge boon to caching (more on this shortly).
Whenever a product is created, updated or deleted, the hydrator's local key-value storage is updated. This is based on the idea that every DB write should be put into a queue. The result is that once we've received a response with an X-Hydrate header, we can parse out the ids and types and issue something like a redis mget to build the real response (or we could use LevelDB, or an RDBMS, or...).
Part 2 has some actual code
Caching
When you bring caching and hydration together, you can see a massive positive impact on your cache hit ratio. For most systems, I'm a big believer in long cache TTLs with proactive purges. Again, using our queue, when product X gets updated, one of the queue workers sends out a purge request. Without hydration though, what do you purge?
You can PURGE /products/X, but what about all those lists of products, either from searching, filtering, paging, curated lists, recommendation, and so on? How do you purge all of the pages that product X belongs to?
With hydration, that isn't a problem. You cache the unhydrated list (preferably in a parsed format) separately from the product data. So you can have a hundred lists which reference product X, but they'll always hydrate on-demand with the most up-to-date data.
The impact on caching is more than just being able to set a long TTL. It can also reduces the size of your cache. Your lists become a fraction of their original size by only containing references rather than full blown objects.
Response Variations
Some services might want to return a slightly different product structure. For example, your full text search service might want to add a weight field.
There are two solutions to this. We can either nest the reference:
{
"page": 1,
"total": 54,
"results": [
{
"weight": 1.0,
"product": {
"!ref": {
"id": "9001p",
"type": "product"
}
}
},
...
]
}
Which would get expanded into:
{
"page": 1,
"total": 54,
"results": [
{
"weight": 1.0,
"product": {
"id": "9001p",
....
}
},
...
]
}
Or return two different objects:
{
"page": 1,
"total": 54,
"results": [
{
"!ref": {
"id": "9001p",
"type": "product"
}
},
...
],
"weights": [1.0, ...]
}
Conclusion
Ultimately the goal is to make it possible to build any number of services without having to either repeat code or couple them. It's also very much about performance. Giving the hydrator it's own key-value store of data, and updating it asynchronously eliminates much of the SOA overhead you'll have. By leveraging that same update channel to proactively purge caches, we can set very long TTLs in our internal caches and not have to worry about stale results.
Part 2 will have actual code :)
Finally, if you're building something using SOA, the hydrator is just a small part in a infrastructure layer you'll likely have sitting at the top of your request pipeline. This system is going to do a lot of things: early SSL termination, routing, logging, some authentication, hydration and caching.