Building Technology Agnostic Globally Distributed Systems
Nov 05, 2013
Introduction
Not long ago, building globally distributed systems was largely the domain of technology behemoths which controlled both their own infrastructure as well as considerable engineering resources. Everyone else, representing the vast majority of systems, deployed to a single location.
Yet the world is getting increasingly connected. Populous developing countries continue to see an ever-improving quality of life. And, English strengthens its roots. The result isn't a shift away from North-America & Europe, but rather a growing audience for you to target.
Within this new climate, the single location approach continues to be viable. But it is not optimal. On a global scale, physics become noticeable. This is exasperated twofold: first, by developers who sit relatively close to the production location while using disproportionately powerful machines; second, by the far from ideal way traffic is routed.
Building distributed systems isn't trivial. But if we're talking about a typical system, one where reads heavily outweigh writes and which doesn't measure it's core data in petabytes, it isn't that hard either. This won't outline a silver bullet, but it should give you a framework to start a conversation around building globally distributed systems.
Above all else, at this level, it's important to remain technology agnostic. I will point out that even the mightiest cloud vendors add little value with respect to globally distributed systems.
The Four Types of Data
We begin by breaking down our data into four categories. Either it must be immediately consistent, or it mustn't. Either it must be near a particular user (or group of users), or it mustn't. This creates four possible combinations:
- Strong consistency, high latency
- Weak consistency, low latency
- Weak consistency, high latency
- Strong consistency, low latency
Let us consider an online store, which I assume has a high read to write ratio while not requiring petabytes of data. What are examples for an online store which fit into each category?
The most obvious example of data which should be immediately consistent but which isn't latency sensitive is the CMS portion of a system. Consistency is important since users must immediately see their changes take effect within the CMS. Latency, though, isn't [as] important since, proportionally, few users manage content (it could even be internal/staff only). Furthermore, waiting 500ms for an edit to post simply seems more tolerable than waiting the same time for a page to load while browsing the store.
For most systems, the bulk of data will fall within the second category which doesn't have strong consistency requirements but should be fast. This is represented by the actual store itself - the item categories, the items themselves, the search and so on.
Data which neither has strong consistency nor latency requirements often serves somewhat secondary purposes, such as the number of people who liked an item as well as general metrics and analytics data.
Shopping carts and wishlists are examples of data which should be immediately consistent while being latency sensitive. Practically any user-specific data falls within this category.
Strong Consistency, High Latency
Data which must be consistent but which doesn't have rigid latency requirements should be managed from a single location, which we call Central. It'll be backed by a durable storage engine with a thought-out (and tested!!) backup strategy. This data will represent the authoritative state of the system. It will likely be well normalized and can be imported/transformed into the internal reporting system.
There's no magic here.
Weak Consistency, Low Latency
For simple systems, Content Delivery Networks (CDN), fed from Central, can fulfill this important piece. However, CDNs are largely a simple key-value store which greatly limits our capabilities.
Instead, edge locations should be asynchronously fed data from Central. One solution is to commit changes both to Central's database and a durable queue. A worker picks up the change, transforms the data as needed and sends it to each edge. Depending on the scale of transformation, edge locations can see changes within seconds. Large changes, such as updating a search index, can be done on schedule in a batch process.
This queue-based asynchronous approach has a few advantages. First, it decouples the systems. Central knows nothing about edges, edges know nothing about central. It also decouples one edge from the other, increasing system resilience. Second, it allows for a distinct write-friendly data model in Central and read-friendly model at the edges (with the workers responsible for the necessary transformation).
Our approach has been to pick up changes, make the necessary transformation (a lot of denormalization) and queue the transformed message onto an edge-specific queue for all edges. Each edge has its own lightweight worker which picks up the transformed messages and synchronizes them. This way, the expensive transformation only happens once, regardless of the number of edges. More importantly, the edges become isolated from each other. If one edge fails or falls behind, its queue will build up, without impacting the others. Note that it's important to process messages in order. To accomplish this, you'll want to make message processing idempotent.
The critical piece is to properly identify and limit what data must be propagated. For example, given a properly designed and robust CMS, only public data need be synchronized.
Subjectively, this is the funnest part to build.
Weak Consistency, High Latency
At a design level, this isn't a real bucket. Any of the other categories can fulfill its requirements. The simplest and thus recommended approach, is to treat it as Strong Consistency, High Latency data and rely on Central.
The exception to the above recommendation is infrastructure and analytics data. More than likely, due to the volume, this data should be collected at the edges and asynchronously copied into Central (there are a great number of open source libraries that can help with this problem).
Strong Consistency, Low Latency
The most difficult data to deal with, unsurprisingly, must both be consistent and fast. If the data must be fast from all edges, there's little choice but to synchronize writes to all locations. Thankfully, master-to-master synchronous replication (or something similar) is something many modern NoSQL solutions provide.
However, data which falls into this category can often be isolated to a single edge; namely when the data belongs to a user. In this case, the edge which the user first connects to becomes the authoritative source. Any other edge which receives a request for the data proxies to the authoritative location. The Coordinator, explained next, is meant to help address the fragility of this approach.
Coordinator
Externally, this categorization is largely invisible (writers to central might notice a delay for their changes to propagate to the public web, but that's about it). This is all thanks to a single layer, which sits at the edge, called the Coordinator.
(Above the Coordinator sits DNS which distributes request to the nearest edge (using AnyCast or some other form of latency based routing). DNS' role here is hopefully obvious.)
The Coordinator is route-aware and knows whether a request should go to the local edge, be proxied to Central or be proxied to a different edge. It knows that POST /v1/items/847.json should be routed to Central and that GET /v1/items/847.json can be fetched from the local edge. The only difficulty is in knowing whether or not GET /v1/users/448/wishlist.json should go to a non-local edge.
The simplest but ugly solution is to embed location-information within the user-id. Receiving a request for GET /v1/items/847_fr.json, a Coordinator knows to proxy through to fr.api.domain.com. A more flexible alternative is to make all Coordinators statefully location-aware. That is, when a user registers in France, all other Coordinators are asynchronously updated (through Central). This way, user data can be migrated from one location to another. Migrating users might happen if they move (this could be automatically detected) or when new edge locations are added or removed.
As you can see, the Coordinator is just a reverse proxy. This not only means that any popular software can be used, but also that it can serve many other functions (it can act as an cache, it can do SSL termination, compress content, and so on).
Conclusion
The design isn't only externally invisible, it's also internally transparent. All the components are built using whatever approach you prefer and whatever tool you wish to use. From this designs point of view, Central is a single location, but internally you can use multiple availability zones and a high availability distributed NoSQL engine. This also applies at the edge, which can be completely standalone or use asynchronous replication with automated fallback with one of multiple other edge locations. In fact, edges can simply be the exact same codebase and data model as Central, but distributed (where's the fun in that though?!).
This doesn't work for all systems, especially very large systems or systems with significant writes. But it doesn't have to be applied to the entire system. Many systems can be logically broken down. Maybe your real-time chat will require its own unique approach. That's ok. But the rest, or part of it, might snugly fit within this framework.
Beyond depending on the thorough understanding of your own data, the fundamental shift required to building distributed systems comes down to asynchronous processing. The write to the queue is as fundamental and critical as the write to the database (seriously, put the queue write inside the DB writes transaction). Once the infrastructure is in place to reliably track changes made to the system, decisions on when, how and where data needs to go is made on case-by-case basis. Most existing queues can handle an impressive amount of throughput. Nevertheless, as a critical components, the queue should provide durability guarantees and scalability options.
As a diagram (blue lines representing asynchronous flows):
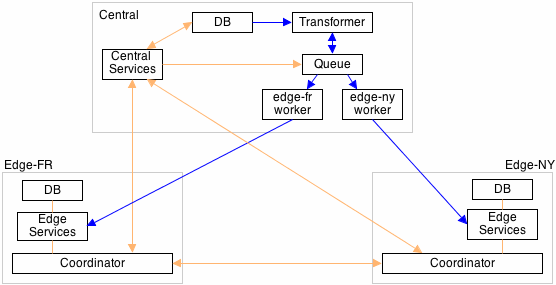
Like any design patterns, this is a work in progress. I welcome any feedback and suggestions.